


Tokenomics
Navigating the Complexities of Pricing and Infrastructure in LLMs and AI Agents


In the last couple of articles, I focused on economics of hosting a private model and economics of AI Agents in the context of inference-time compute. In this article, I will focus on token economics of LLMs.
A token is a fundamental unit of text processing in a LLM. It can represent words, character sets, or combinations of them that the model uses to analyze text. LLMs convert tokens to unique numerical representations, enabling them to efficiently process language.
Example: The sentence "What is the capital of France?" could be tokenized as:
["What", "is", "the", "capital", "of", "France", "?"]
Tokens - the currency of LLMs
Tokens are the basic unit of transaction with an LLM and the basis for monetization, hence can be considered the currency of LLMs. When using LLMs, users are typically charged based on the number of tokens processed, both for input tokens (the text sent to the model) and output tokens (the text generated by the model). This token-based pricing model allows for precise tracking and billing based on actual LLM usage.
Companies are experimenting with different ways to monetize LLMs based on tokens. Here are some variations of token based pricing
Input vs. Output Tokens: charge differently for input and output tokens, with output tokens typically costing more
Volume-Based Pricing: tiered pricing based on usage volume
Simplified Pricing: flat rates regardless of token volume
Context Window based: models with larger context windows (e.g., 128k, 200k, or even 1M+ tokens) often have different pricing structures
Realtime vs. Standard Models: Some providers offer "realtime" versions of models at different price points, like OpenAI's GPT-4o Realtime
Variations across Providers: cost per 1k tokens varies across models and providers
The cost per token for LLMs has been rapidly decreasing over the past few years - an average of 10x annual decrease and 1000x decrease in 3 years. In November 2021, GPT-3 (with an MMLU score of 42) cost $60 per million tokens. By 2024, models like Llama 3.2 3B (with the same score) for just $0.06 per million tokens.
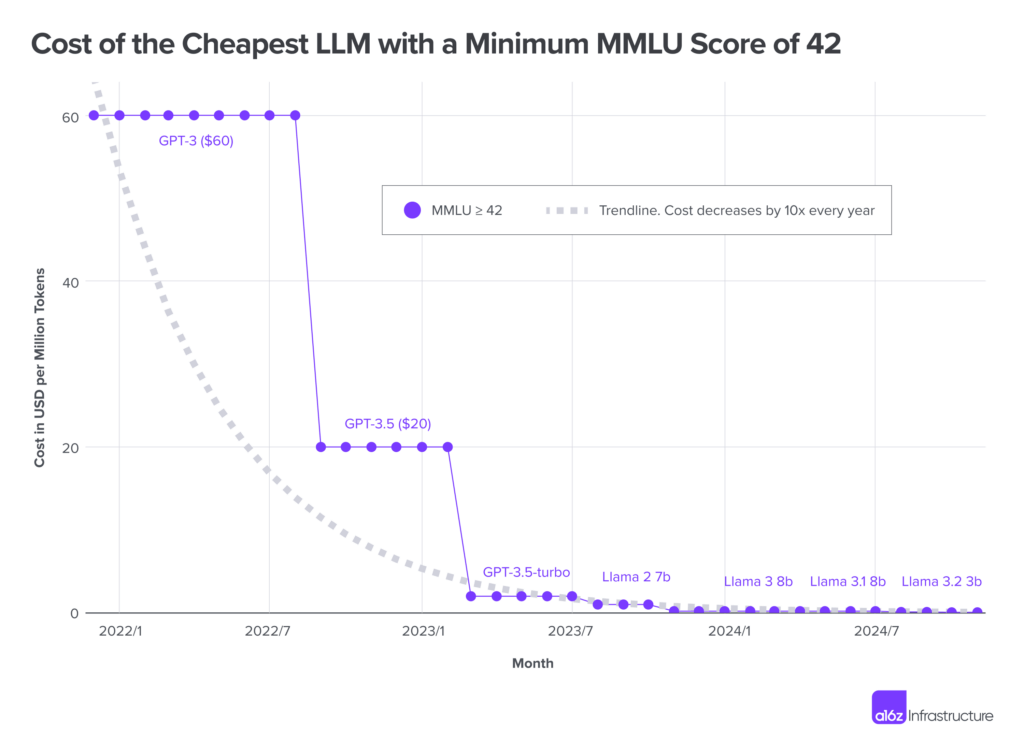
It is great that the cost per token has rapidly come down. But that is only half the story. The economics are much more complex than that. Let us analyze further.
How AI inference is different from traditional SaaS
As discussed in my previous article, an AI Agent does a lot of computation for each task, which involves using one or more GPUs. This means, there is a high operational cost (saddled by GPU costs) to run the inference tasks. This is a bit different from traditional cloud and SaaS apps, especially in the context of scaling.
Traditional SaaS applications mostly use CPUs, which are much cheaper compared to GPUs. CPUs enable efficient multitasking, allowing multiple tasks to run simultaneously. This capability maximizes infrastructure utilization, enabling incremental scaling as application demands grow. Scaling with CPUs often requires step-like increases in infrastructure when the current footprint is outgrown.
In contrast, GPUs are optimized for parallel processing, making them ideal for AI inference tasks that require handling large datasets concurrently. While GPUs can process multiple inference jobs in parallel if properly managed, the high upfront cost and the need for specialized infrastructure can make scaling seem more expensive. Unlike CPUs, GPUs require careful workload distribution to achieve optimal utilization, and their cost can introduce a different scaling dynamic compared to traditional CPU-based systems.
Token economics for Cloud and Private models
The AI Agents could either use a cloud model or a private model or a hybrid scenario based on the job at hand and data privacy needs. They both use token based pricing, but the implications are slightly different in each case. Let us examine how.
Cost-Plus implications for Cloud models
AI agents, powered by cloud LLMs, perform tasks such as data analysis, decision-making, and automation. These tasks require processing text inputs and generating outputs, which are billed according to the token pricing model. The cost of using LLMs becomes a direct capital expense (and operational expense too) for AI agents. This expense is added to other costs such as infrastructure, maintenance, and development, making it a cost-plus structure for the Agent's services.
A value-based pricing is the right pricing approach and will be considered by many AI Agent providers. However, value-based pricing requires
Quantifying efficiency improvements and productivity gains achieved by using AI agents
Articulating customer benefits such as personalized experiences
Differentiating from competitors can be challenging when using cloud models, especially when facing providers of advanced models and companies like Perplexity, which benefit from economies of scale and offer freemium pricing.
Token economics for Private models
I have analyzed the economics of private models in my previous article. Hosting private models can be expensive, but is necessary for companies building AI Agents based on private data.
Private models require the following
Fixed costs - Infrastructure setup to host the model, model training/fine tuning and ongoing maintenance
Variable costs - Compute resources needed per query (inference) and associated costs such as API costs for any external services, data storage and retrieval costs
Assumptions
Let us anchor on Perplexity AI pro-tier pricing at $20 per month for 500 queries
Average query length is 1000 tokens in this example
Fixed costs of $1,000,000 in this example
Variable cost of $0.001 per token in this example - rationale
Cloud model pricing - OpenAI's pricing for GPT-3.5 Turbo is $0.0015 per 1,000 input tokens and $0.002 per 1,000 output tokens
Self hosting costs - self-hosted DBRX Base model can be as low as $0.000158 per token. However, this cost does not include additional expenses like maintenance, updates, and upgrades
These assumptions and analysis below are for illustration purposes. Actuals can vary based on specific scenarios, and the results will vary accordingly.
Analysis
Revenue per token = ($20 / (500 * 1000)) = $0.00004 per token
Breakeven tokens = Fixed costs / (Revenue per token - Variable cost per token)
= $1,000,000 / ($0.00004 - $0.001)
= 1,041,666,667 tokens
= 1,041,667 queries
Profit per token: $0.00004 - $0.001 = -$0.00096 (loss per token)
This means that the business operates at a loss of $0.00096 per token until it reaches the breakeven point.
Test Time Compute costs
Test time compute (TTC) a.k.a. inference-time compute often involves additional processing during inference to improve results e.g. multiple model passes, breaking queries into sub-questions (reasoning / Chain of Thought) etc.
Let's assume TTC increases the cost per token by 50%:
New variable cost per token = $0.001 * 1.5 = $0.0015
With TTC, the new breakeven point becomes:
Breakeven tokens = $1,000,000 / ($0.00004 - $0.0015)
= 684,931,507 tokens
= 684,932 queries
Profit per token: $0.00004 - $0.0015 = -$0.00146 (loss per token)
With TTC, the breakeven point is reached sooner, but the loss per token increases due to higher costs. This means that while the business reaches breakeven sooner in terms of volume, it does so with a lower profit margin or a larger loss per token until breakeven.
Choice of GPU on token economics
The choice of GPUs plays a key role in token economics. For example, let's look at H100 vs A100.
H100 vs. A100 Performance
Cloud providers typically charge more for H100 instances compared to A100.
H100 instances cost about $4-$5 per hour per H100 GPU (depends on reserved vs standard etc.)
A100 instances cost about $2-$3 per hour per A100 GPU
However, the superior performance of H100 can offset the increased cost in certain scenarios. So the choice requires careful consideration of Agent / workload requirements, performance, costs etc. It is important to make these choices carefully as it will have huge implications on the economics and viability.
Token economics for cloud vs self hosting
To choose cloud vs self hosting, we can do this simple analysis to calculate how many tokens are needed breakeven to justify investment in self hosting. The self hosting in this context could be either to host the model on-prem or privately on the cloud.
Breakeven point (tokens) = Initial investment / (Cloud API token cost - Self-hosted token cost)
How to make token economics work?
As we see from the above calculations, here are the levers to play with
Fixed costs - minimizing fixed costs is challenging since they form the foundation of service offerings. But it is critical to make the right GPU selection that offers best performance-to-cost ratio, minimize infrastructure costs and implement efficient data storage and processing
Revenue per token - increasing revenue per token can be achieved by offering value-added services that justify higher pricing. They include enhanced security, personalized/custom models tailored to specific industries or applications resulting in more value-added outcomes
Variable costs - reducing variable costs involves implementing optimizations and efficiency measures. Some possibilities include model size pruning, minimizing number of passes needed for inference, knowledge distillation from large models to smaller ones to reduce computational costs
The key to success of AI Agents will be the variable costs (TTC). NVidia is the 800 pound gorilla in the market with over 75% margins. It is unlikely NVidia will part with the margins until new contenders offer alternative chipsets that are more cost and energy efficient. There are many new age silicon startups building inference chipsets.
The success of these silicon alternatives will be key to the success of the AI Agent market as well.
Conclusion
Token economics for LLMs is a rapidly evolving field, driven by technological advancements and business model innovations. As the cost per token continues to decrease, companies will have to navigate complex pricing strategies and infrastructure choices to remain competitive while creating customer value. The future of token economics will be shaped by advancements in GPU technology, emerging silicon alternatives to NVidia, and innovative pricing and business models.