


Private Model Economics for Enterprise AI
Why smaller private models are the key to balancing data privacy with costs


In my previous article, I have discussed data privacy related implications for enterprises related to AI, and a possible hybrid approach for enterprises to use a combination of cloud and private models. In this article, I want to evaluate the cost of running private models for enterprises.
For the purposes of this evaluation, I will use DeepSeek 671B, which should be a proxy for similar large language models of its size. The model can be hosted either in a private cloud or privately in a public cloud on AI-optimized instances.
To run a LLM such as DeepSeek 671B in a private cloud requires significant hardware resources, and can be prohibitively expensive for many enterprises (based on many estimations from users who have tried it).
Hardware requirements for full scale model on a private cloud:
For Training:
GPUs: 24-32 NVIDIA H100 80GB GPUs
CPU: High-end multi-core processors
RAM: 1-2TB of system RAM
Storage: Several terabytes of high-speed SSD storage (for model plus data)
For Fine-tuning:
GPUs: 24 NVIDIA H100 80GB GPUs (minimum)
CPU: High-performance multi-core processors
RAM: 384-512GB of system RAM
Storage: 1-2TB of SSD storage
Estimated costs for full scale model on a private cloud
Hardware Costs:
NVIDIA H100 80GB GPUs: $10,000-$15,000 per GPU
Total GPU cost: $240,000-$480,000 for 24-32 GPUs
Server hardware (CPUs, RAM, storage): $50,000-$100,000
Total hardware cost: $290,000-$580,000
Additional Costs:
Power supply capable of delivering 10.2kW or more
Cooling systems to manage heat output
Networking equipment for high-speed data transfer
Operational costs such as maintenance and support
These costs can run in the order of millions of dollars a year
Cloud alternative for full scale model
Alternatively, the LLM can be hosted privately on public cloud. But this is not any cheaper.
Using cloud services like AWS or GCP: $98-$124 per hour for AI-optimized instances
This translates to approximately $2,352-$2,976 per day or $70,560-$89,280 per month for 24/7 operation
Quantized models
An alternative is to use quantized models. Quantized models are compressed versions of LLMs where the weights and activations are converted from high-precision data types (like 32-bit floating-point) to lower-precision formats (such as 8-bit integers).
A full scale model uses 32-bit floating point (FP32), offering 100% accuracy (that the model can offer) but also requires more computational resources. Trading off to FP16, INT8 to INT4 can reduce system requirements (and costs) signicantly, making it faster, but at the cost of accuracy. The decision to tradeoff would be based on use cases and the tolerance to reduction in accuracy.
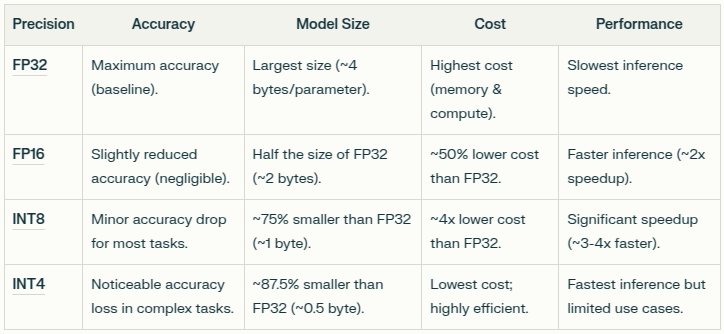
In the context of DeepSeek 671B, it is the dynamically quantized version DeepSeek R1 671B model, for which the hardware requirements and costs are significantly reduced.
Hardware requirements for quantized version
GPU: Single high-end consumer GPU or enterprise-grade GPU (GPUs with higher VRAM needed for better performance. Enterprise workloads may still require multi-GPU setups even with quantization)
CPU: Modern multi-core processor
RAM: 80-96GB system RAM
Storage: 1-2TB of SSD storage
Estimated costs for quantized version
Hardware Costs:
GPU: NVIDIA RTX 4090 (24GB VRAM) or NVIDIA A5000/A6000 (24-48GB VRAM): $1,500-$5,000
CPU: High-end consumer or workstation CPU: $500-$1,000
RAM: 96GB DDR4/DDR5: $300-$500
NVMe SSD (2TB): $200-$300
Total hardware cost: $2,500-$6,800
Additional Costs:
Significantly reduced power, cooling, operational costs than full model due to reduced power consumption
The quantized models can run on consumer-grade hardware without enterprise-class GPUs or servers.
Cloud Costs for running quantized model
Running the dynamically quantized DeepSeek R1 model in the cloud will be significantly more cost-effective than running the full model:
The hourly cost ranges from $5/hour (for A100 GPUs e.g. GCP A2) for smaller instances to around $24/hour (for H100 GPUs e.g. AWS P5) for a typical setup with two GPUs.
This translates to $120-$576 per day or $3,600-$17,800 per month for 24/7 operation
This makes dynamic quantization a practical option for enterprises looking to balance performance with cost while leveraging cloud infrastructure for LLM inference workloads. However, this can still be expensive for many enterprises - especially if they want to run these models 24/7.
Smaller models and tradeoffs
Smaller models (e.g. DeepSeek R1-Distill-Qwen 7B to 70B parameters or similar ones from others) can further reduce the computational needs by an order of magnitude. But the choice depends on
Use cases: larger models with larger context windows are suited for complex reasoning tasks, long-form content generation and smaller models for specific tasks. Some examples for smaller models include
Healthcare: Analyzing patient records while ensuring HIPAA compliance.
Finance: Risk assessment using proprietary financial data.
Customer Support: Automating responses using internal CRM data.
Accuracy and Performance: smaller models will have reduced accuracy compared to larger ones. So they are suitable for specific tasks
Computational resources: smaller models will have reduced computational requirements
Scalability: smaller models offer better scalability and cost-effectiveness for businesses with high API traffic
Total cost of ownership (TCO) should be calculated, including power, cooling and operational costs, for making the right tradeoffs for models and hosting choices.
Conclusion
Smaller private language models offer enterprises an excellent solution to balance cost, efficiency, scalability, and privacy. By training these models on proprietary internal data such as documents, emails, and databases, enterprises can handle domain-specific tasks securely while maintaining compliance with regulations.
A hybrid approach could balance privacy and costs.
Sensitive data is processed by private models.
General reasoning tasks are offloaded to public LLMs.
Technologies like Retrieval-Augmented Generation (RAG) and LangChain can integrate private data sources with public LLMs to provide seamless outputs.