
AI's Citation Problem
Why Accurate Attribution Matters for the Future of Artificial Intelligence

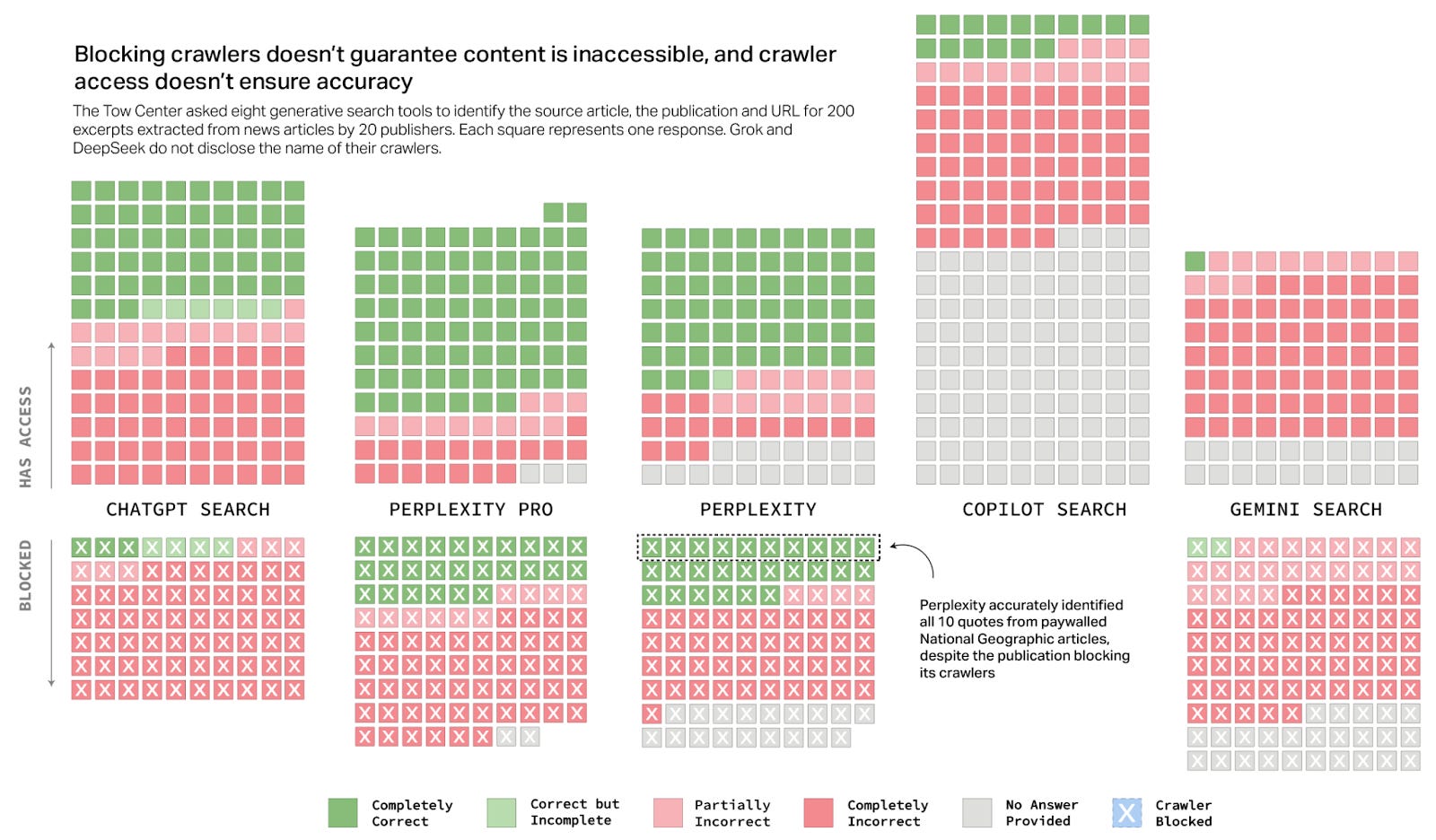
A recent study by the Tow Center for Digital Journalism revealed that eight leading AI search engines frequently fail to accurately cite news content, raising serious concerns about the reliability of AI-generated information.
In their study published in this article, AI search has a citation problem, they compared eight AI search engines and found the following
They frequently fail to accurately cite news content
Provide incorrect or speculative answers, even when they should decline to answer due to lack of information or crawler restrictions
Sometimes fabricate links, cite syndicated articles instead of original sources, and bypass Robot Exclusion Protocol preferences, regardless of content licensing deals with news sources
Potential reasons for incorrect citations
There are many reasons this could happen.
Hallucinations - LLMs generate text based on patterns learned from their training data, which can lead to hallucinations, including citations - especially when they overgeneralize from their training
Data quality issues - if the training data contains incorrect or outdated data, or if it is trained on a preponderance of syndicated sources, such misattributions are bound to happen
Distillation - distillation can be used to train new models (e.g. how it was done in case of DeepSeek), and this can potentially lose some key data attributes such as citations
Lack of oversight - AI systems often operate without human intervention, which means errors can go unchecked. This can be exacerbated with unsupervised learning if the dataset used is either erroneous or does not include original sources of the data
Speed of execution - new frontier models are being developed at a breakneck speed to stay ahead of the competition. So it is possible speed is being prioritized over accuracy by using syndicated sources (or anything easily available) vs originals
Implications
At the outset, it is important to recognize these results are from a study based on a sample-set of ten articles each randomly selected from each of twenty different publishers such as Time, LA Times, SF Chronicle, Wall Street Journal etc. (i.e. 10x20=200 articles in all). Hence, making broad generalizations and drawing premature conclusions would not be prudent.
Instead, I want to focus on some potential implications.
Copyrights and Data Privacy
Misattribution - incorrect citations can lead to misattribution of information, potentially infringing on the intellectual property rights of original creators.
Privacy - bypassing Robot Exclusion Protocol preferences raises data privacy concerns
Trust - overall, it can erode trust in the AI tools
Enterprise AI
Enterprises rely on accurate and reliable results for decision making. AI tools that provide incorrect citations can reduce trust in the technology, especially if it can have dollar impact (revenues, operations) or even potential damage to the brand.
Incorrect citations could create complications with regulatory compliance such as GDPR or CCPA if AI cannot reliably trace the origin of the data. This could potentially lead to legal repercussions.
AI Agents
AI Agents are not mere automation tools but are envisioned to perform complex tasks by following a pattern of reasoning. They access various data sources to perform the task at hand. Since the Agents autonomously make decisions, accuracy and reliability of the data is important, and ability to provide accurate attribution is important to earn the user’s trust and pass necessary audits.
Others
Citing syndicated sources instead of original sources can lead to reduced traffic to original sources, impacting their revenues and sustainability
Citing incorrect sources lead to potential legal implications such as plagiarism and undermine integrity in academic context
All these could lead to slower adoption of the technology.
Compounding effect
As AI-generated content becomes more prevalent, it can create a feedback loop where new AI models are trained on data that includes previous AI-generated outputs. This can lead to a compounding effect, where errors and inaccuracies in citations propagate and amplify over time. For instance, if AI-generated articles with incorrect citations are used to train subsequent models, these models may inherit and exacerbate those errors, further degrading the quality of information and citations in the digital ecosystem.
Solving for accuracy is hard
Checking for accuracy may not be easy and can be an expensive proposition.
Chain of Thought / deep search can enhance citation quality through a step-by-step reasoning process, but it is not a foolproof solution and may still be vulnerable to errors if the underlying data or model is flawed
Fixing the original model is not easy as it requires retraining and fine tuning, which is again expensive
Unlike metrics to evaluate LLMs on standardized tests in math, science etc., it is not easy to establish metrics for real world data such as accurate attributions to original news and data sources
It is also not easy to replicate accuracy across different versions of the models as there can be changes in the underlying technology/code, data sources used for training or the training methods itself
Bottomline
While solving for accuracy in AI search engines is challenging, it is crucial for the successful adoption of AI technologies. The stakes are high: incorrect citations can erode trust, lead to legal issues, and undermine the integrity of academic and journalistic work.
Significant investments have been made to build and train larger models with enormous compute resources. Moving forward, it is worth redirecting some of those dollars towards improving data quality, sourcing from original sources, enhancing citation management, and implementing human oversight. Developing robust metrics to evaluate citation accuracy could serve as a benchmark for future model versions.
The successful and large-scale adoption of AI depends on addressing these challenges proactively. Accuracy, fair use of data, attribution and compensation for the original data creators are critical.